Wie funktioniert Archivarix?
Das Archivarix-System dient zum Herunterladen und Wiederherstellen von Websites, auf die im Webarchiv nicht mehr zugegriffen werden kann, sowie von Websites, die derzeit online sind. Dies ist der Hauptunterschied zu den anderen "Downloadern" und "Site-Parsern". Ziel von Archivarix ist nicht nur das Herunterladen, sondern auch das Wiederherstellen der Website in einer Form, auf die auf Ihrem Server zugegriffen werden kann.
Beginnen wir mit dem Modul, das Websites aus dem Webarchiv herunterlädt. Dies sind virtuelle Server in Kalifornien. Ihr Standort wurde so gewählt, dass die höchstmögliche Verbindungsgeschwindigkeit mit dem Webarchiv selbst erzielt wird, da sich die Server in San Francisco befinden. Nachdem Sie Daten in das entsprechende Feld auf der Seite des Moduls https://de.archivarix.com/restore/ eingegeben haben, wird ein Screenshot der archivierten Website erstellt und die Web Archive API aufgerufen, um eine Liste der zum angegebenen Wiederherstellungsdatum enthaltenen Dateien anzufordern .
Nachdem das System eine Antwort auf die Anfrage erhalten hat, generiert es eine Nachricht mit der Analyse der empfangenen Daten. Der Benutzer muss nur die Bestätigungstaste in der empfangenen Nachricht drücken, um den Download der Website zu starten.
Die Verwendung der Web Archive API bietet zwei Vorteile gegenüber dem direkten Download, wenn das Skript einfach den Links der Website folgt. Zunächst sind alle Dateien dieser Wiederherstellung sofort bekannt. Sie können das Website-Volumen und die zum Herunterladen erforderliche Zeit abschätzen. Aufgrund der Art des Webarchivierungsvorgangs funktioniert dies manchmal sehr instabil, sodass Verbindungsunterbrechungen oder ein unvollständiger Download von Dateien möglich sind. Daher überprüft der Modulalgorithmus ständig die Integrität der empfangenen Dateien und versucht in solchen Fällen, den Inhalt durch erneutes Herstellen einer Verbindung mit herunterzuladen der Web Archive Server. Zweitens können aufgrund der Besonderheiten der Website-Indizierung durch Web Archive nicht alle Websitedateien direkte Links enthalten. Wenn Sie also versuchen, eine Website einfach durch Folgen der Links herunterzuladen, sind diese nicht verfügbar. Die Wiederherstellung über die von Archivarix verwendete Webarchiv-API ermöglicht es daher, die maximal mögliche Menge an archiviertem Website-Inhalt für ein bestimmtes Datum wiederherzustellen.
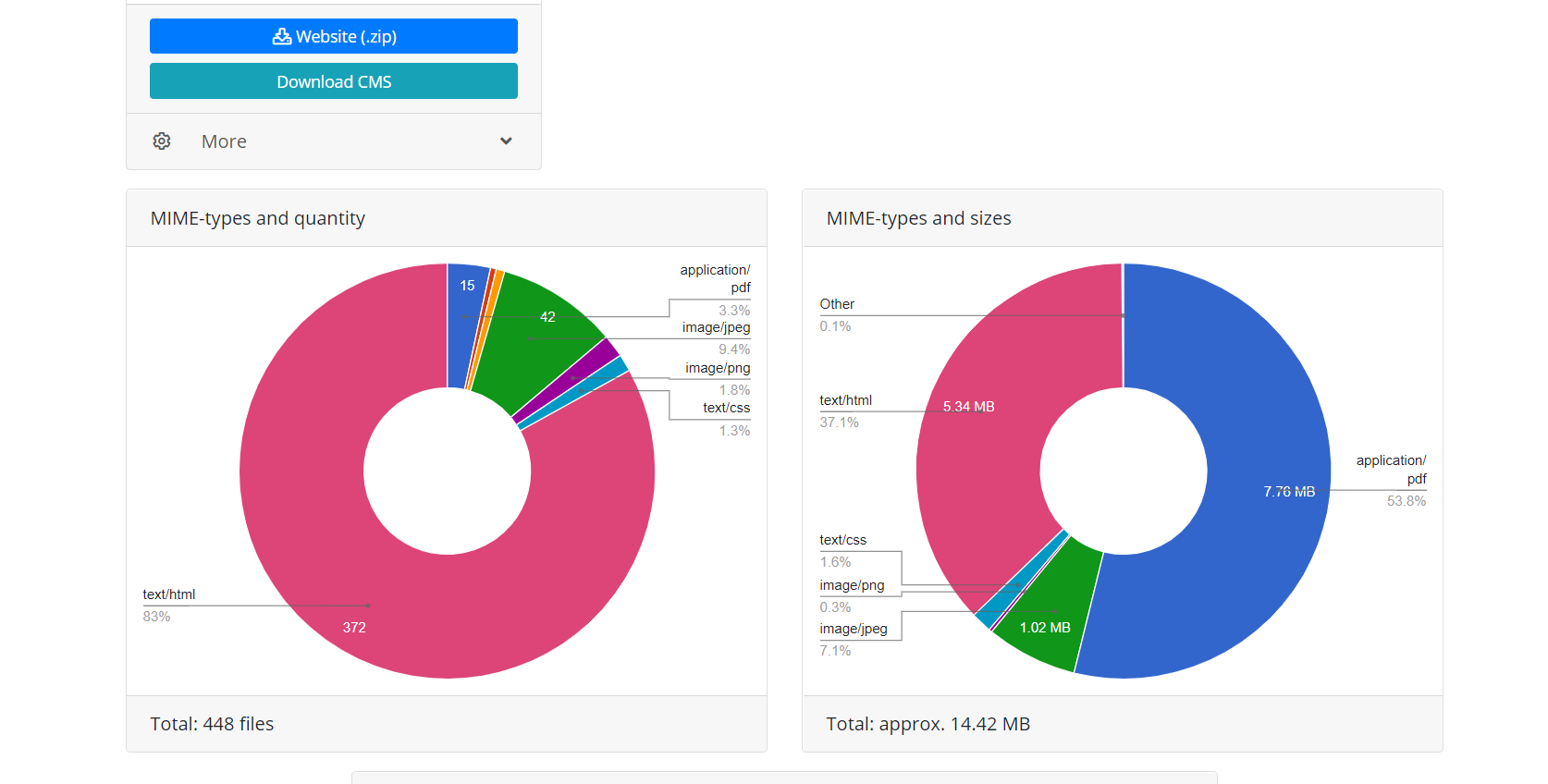
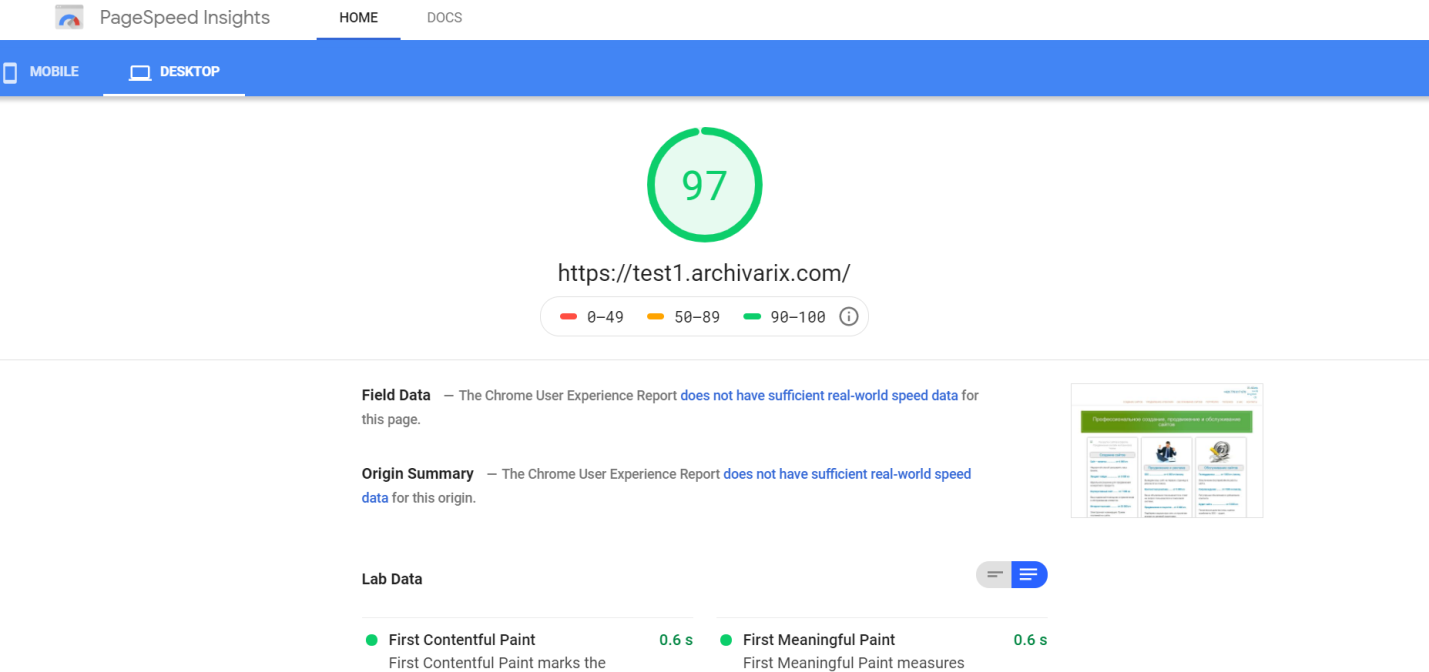
Nach Abschluss des Vorgangs überträgt das Download-Modul aus dem Webarchiv Daten an das Verarbeitungsmodul. Es bildet eine Website aus den empfangenen Dateien, die für die Installation auf einem Apache- oder Nginx-Server geeignet sind. Der Website-Betrieb basiert auf der SQLite-Datenbank. Um zu beginnen, müssen Sie diese lediglich auf Ihren Server hochladen. Es ist keine Installation zusätzlicher Module, MySQL-Datenbanken und Benutzererstellung erforderlich. Das Verarbeitungsmodul optimiert die erstellte Website; Es beinhaltet Bildoptimierung sowie CSS- und JS-Komprimierung. Dies kann die Download-Geschwindigkeit der wiederhergestellten Website im Vergleich zur ursprünglichen Website erheblich steigern. Die Downloadgeschwindigkeit einiger nicht optimierter Wordpress-Sites mit einer Reihe von Plugins und unkomprimierten Mediendateien kann nach der Verarbeitung durch dieses Modul erheblich erhöht werden. Es ist offensichtlich, dass eine anfängliche Optimierung der Website die Download-Geschwindigkeit nicht wesentlich erhöht.
Das Verarbeitungsmodul entfernt Werbung, Zähler und Analysen, indem die empfangenen Dateien mit einer umfangreichen Datenbank von Werbe- und Analyseanbietern abgeglichen werden. Das Entfernen externer Links und klickbarer Kontakte erfolgt einfach durch Prüfsummencode. Im Allgemeinen führt dieser Algorithmus eine recht effiziente Bereinigung der Website von "Spuren des Vorbesitzers" durch, obwohl dies manchmal nicht ausschließt, dass etwas manuell korrigiert werden muss. Beispielsweise wird ein selbst geschriebenes Java-Skript, das den Website-Benutzer zu einer bestimmten Monetarisierungs-Website umleitet, vom Algorithmus nicht gelöscht. Manchmal müssen Sie fehlende Bilder als Spam-Gästebuch hinzufügen oder unnötige Rückstände entfernen. Daher muss ein Redakteur für die resultierende Website eingestellt werden. Und es existiert bereits. Es heißt Archivarix CMS.
Dies ist ein einfaches und kompaktes CMS zur Bearbeitung von Websites, die mit dem Archivarix-System erstellt wurden. Es ermöglicht das Suchen und Ersetzen von Code auf der gesamten Website mithilfe regulärer Ausdrücke, das Bearbeiten des Inhalts im WYSIWYG-Editor sowie das Hinzufügen neuer Seiten und Dateien. Archivarix CMS kann zusammen mit jedem anderen CMS auf einer Website verwendet werden.
Lassen Sie uns nun über ein anderes Modul sprechen, das zum Herunterladen vorhandener Websites verwendet wird. Anders als beim Modul zum Herunterladen von Websites aus dem Webarchiv kann nicht vorhergesagt werden, wie viele und welche Dateien Sie herunterladen müssen, sodass die Server des Moduls auf völlig andere Weise funktionieren. Server Spider folgt einfach allen Links, die auf einer Website vorhanden sind, die Sie herunterladen möchten. Damit das Skript nicht in den endlosen Download-Zyklus einer automatisch generierten Seite fällt, ist die maximale Linktiefe auf zehn Klicks begrenzt. Die maximale Anzahl von Dateien, die von der Website heruntergeladen werden können, muss im Voraus festgelegt werden.
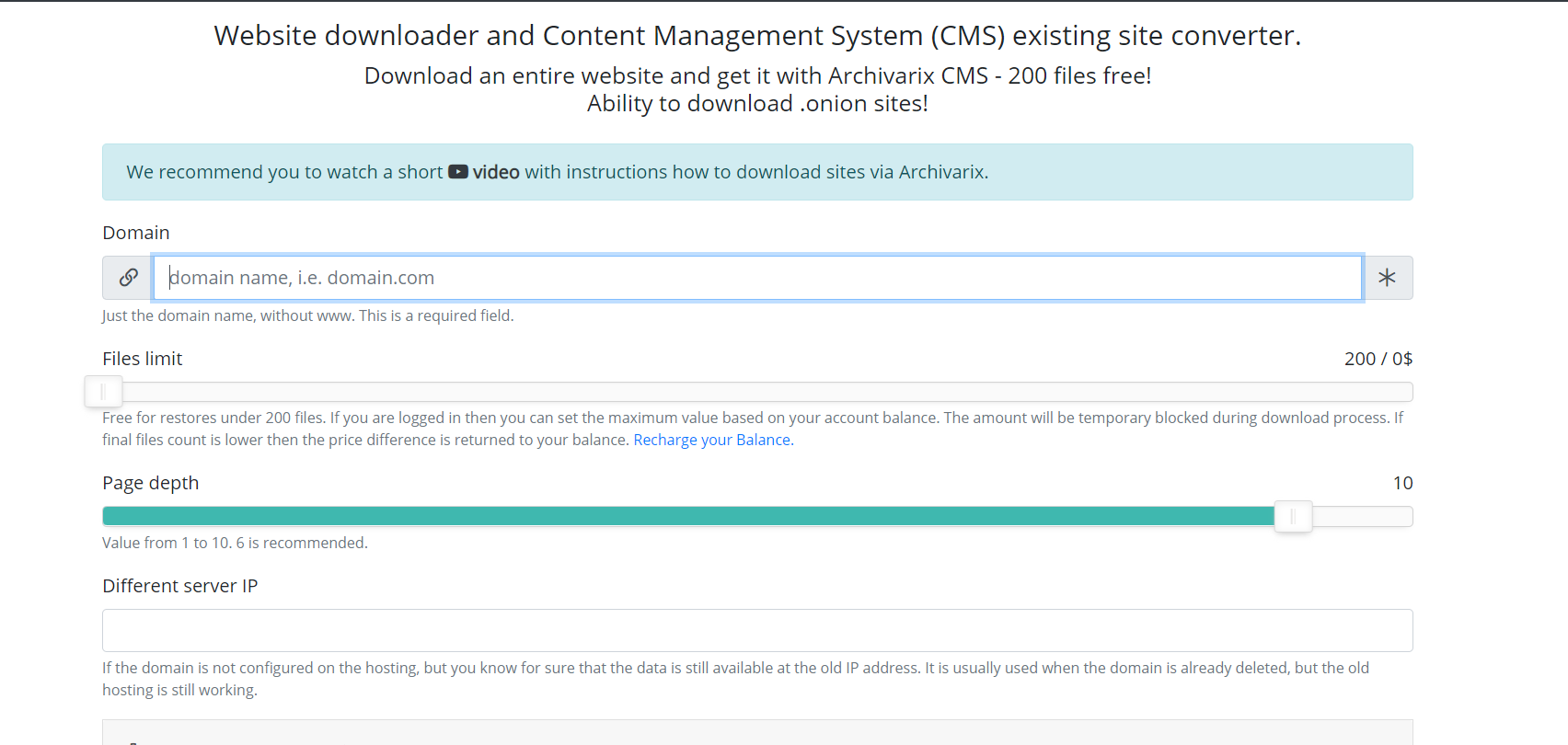
Für das vollständige Herunterladen der von Ihnen benötigten Inhalte wurden in diesem Modul verschiedene Funktionen erfunden. Sie können einen anderen User-Agent-Service-Spider auswählen, z. B. Chrome Desktop oder Googlebot. Referrer für Cloaking Bypass - Wenn Sie genau das herunterladen möchten, was der Benutzer sieht, wenn er über die Suche angemeldet ist, können Sie einen Referrer für Google, Yandex oder eine andere Website installieren. Zum Schutz vor IP-Sperren können Sie die Website über das Tor-Netzwerk herunterladen, während sich die IP-Adresse der Service-Spinne in diesem Netzwerk zufällig ändert. Andere Parameter wie Bildoptimierung, Anzeigenentfernung und Analyse ähneln den Parametern des Download-Moduls aus dem Webarchiv.
Nach Abschluss des Downloads wird der Inhalt in das Verarbeitungsmodul übertragen. Die Funktionsprinzipien ähneln vollständig der oben beschriebenen Funktionsweise der aus dem Webarchiv heruntergeladenen Website.
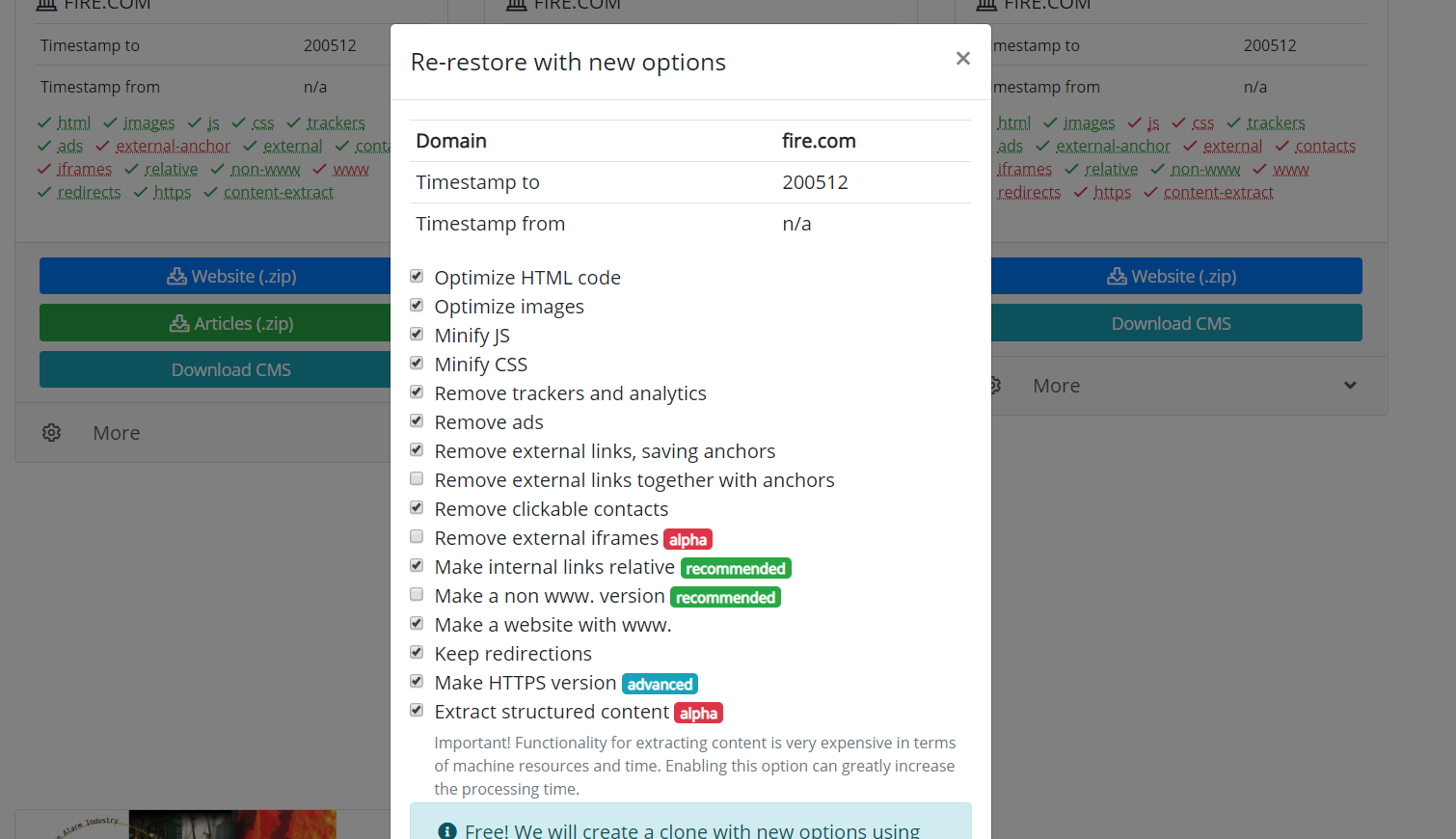
Erwähnenswert ist auch die Möglichkeit, wiederhergestellte oder heruntergeladene Websites zu klonen. Manchmal kommt es vor, dass man während der Wiederherstellung andere Parameter gewählt hat, als es sich am Ende als notwendig erwiesen hat. Das Entfernen externer Links war beispielsweise nicht erforderlich, und einige externe Links mussten nicht erneut heruntergeladen werden. Sie müssen lediglich neue Parameter auf der Wiederherstellungsseite festlegen und die Site neu erstellen.
Die Verwendung von Artikelmaterialien ist nur zulässig, wenn der Link zur Quelle veröffentlicht wird: https://archivarix.com/de/blog/how-does-it-works/

Das Archivarix-System dient zum Herunterladen und Wiederherstellen von Websites, auf die im Webarchiv nicht mehr zugegriffen werden kann, sowie von Websites, die derzeit online sind. Dies ist der Haup…
Mit der Option "Strukturierten Inhalt extrahieren" können Sie auf einfache Weise ein Wordpress-Blog sowohl von der Website im Webarchiv als auch von jeder anderen Website aus erstellen. Suchen Sie daz…
Damit Sie die in unserem System wiederhergestellten Websites bequem bearbeiten können, haben wir ein einfaches Flat File CMS entwickelt, das nur aus einer kleinen PHP-Datei besteht. Trotz seiner Größe…
- Vollständige Lokalisierung von Archivarix CMS in 13 Sprachen (Englisch, Spanisch, Italienisch, Deutsch, Französisch, Portugiesisch, Polnisch, Türkisch, Japanisch, Chinesisch, Russisch, Ukrainisch, Weißrussisch).
- Exportieren Sie alle aktuellen Site-Daten in ein Zip-Archiv, um eine Sicherung zu speichern oder auf eine andere Site zu übertragen.
- Anzeigen und Entfernen defekter Zip-Archive in Import-Tools.
- Überprüfung der PHP-Version während der Installation.
- Informationen zur Installation von CMS auf einem Server mit NGINX + PHP-FPM.
- Wenn bei der Suche im Expertenmodus das Datum / die Uhrzeit der Seite und ein Link zu ihrer Kopie im WebArchiv angezeigt werden.
- Verbesserungen der Benutzeroberfläche.
- Codeoptimierung.
Wenn Sie Muttersprachler einer Sprache sind, in die unser CMS noch nicht übersetzt wurde, laden wir Sie ein, unser Produkt noch besser zu machen. Über den Crowdin -Service können Sie sich bewerben und unser offizieller Übersetzer in neue Sprachen werden.
- Unterstützung der Befehlszeilenschnittstelle für die Bereitstellung von Websites direkt über die Befehlszeile, Importe, Einstellungen, Statistiken, Löschen des Verlaufs und Systemaktualisierungen.
- Unterstützung für verschlüsselte Passwörter password_hash (), die in der CLI verwendet werden können.
- Expertenmodus mit zusätzlichen Debug-Informationen, experimentellen Tools und direkten Links zu gespeicherten WebArchive-Snapshots.
- Tools für fehlerhafte interne Bilder und Links können jetzt eine Liste aller fehlenden URLs zurückgeben, anstatt sie zu entfernen.
- Das Import-Tool zeigt beschädigte / unvollständige Zip-Dateien an, die entfernt werden können.
- Verbesserte Cookie-Unterstützung, um den Anforderungen moderner Browser gerecht zu werden.
- Festlegen der Standardeditorauswahl für HTML-Seiten (visueller Editor oder Code).
- Die Registerkarte "Änderungen" mit Textunterschieden, die standardmäßig deaktiviert ist, kann in den Einstellungen aktiviert werden.
- Sie können auf der Registerkarte "Änderungen" zu einer bestimmten Änderung zurückkehren.
- Die XML-Sitemap-URL für Websites, die mit der WWW-Subdomain erstellt wurden, wurde korrigiert.
- Das Löschen temporärer Dateien, die während der Installation / des Imports erstellt wurden, wurde behoben.
- Schnellere Reinigung der Geschichte.
- Nicht verwendete Lokalisierungsphrasen wurden entfernt.
- Umschalten der Sprache auf dem Anmeldebildschirm.
- Externe Pakete auf die neuesten Versionen aktualisiert.
- Optimierte Speichernutzung zur Berechnung von Textunterschieden auf der Registerkarte Änderungen.
- Verbesserte Unterstützung für alte Versionen der PHP-Dom-Erweiterung.
- Ein experimentelles Tool zum Korrigieren der Dateigrößen in der Datenbank, wenn Sie die Dateien direkt auf dem Server bearbeitet haben.
- Ein experimentelles und sehr grobes Export-Tool für flaches Design.
- Experimentelle Unterstützung öffentlicher Schlüssel für zukünftige API-Funktionen.
- Behoben: Der Abschnitt Verlauf funktionierte nicht, wenn die Zip-Erweiterung PHP nicht aktiviert war.
- Registerkarte "Verlauf" mit Details zu Änderungen beim Bearbeiten von Textdateien.
- .htaccess-Bearbeitungswerkzeug.
- Möglichkeit, Backups bis zum gewünschten Rollback-Punkt zu bereinigen.
- Der Block "Fehlende URLs" wurde aus den Tools entfernt Es ist über das Hauptpanel zugänglich
- Überprüfung und Anzeige des freien Speicherplatzes im Hauptfenster hinzugefügt.
- Verbesserte Überprüfung der erforderlichen PHP-Erweiterungen beim Start und bei der Erstinstallation.
- Kleinere kosmetische Veränderungen.
- Alle externen Tools wurden auf die neuesten Versionen aktualisiert.
- Separates Passwort für den abgesicherten Modus.
- Erweiterter abgesicherter Modus. Jetzt können Sie benutzerdefinierte Regeln und Dateien erstellen, jedoch ohne ausführbaren Code.
- Neuinstallation der Site vom CMS, ohne dass manuell etwas vom Server gelöscht werden muss.
- Möglichkeit, benutzerdefinierte Regeln zu sortieren.
- Verbessertes Suchen und Ersetzen für sehr große Websites.
- Zusätzliche Einstellungen für das Tool "Viewport-Meta-Tag".
- Unterstützung für IDN-Domains beim Hosting mit der alten Version der Intensivstation.
- Bei der Erstinstallation mit einem Passwort wird die Möglichkeit zum Abmelden hinzugefügt.
- Wenn während der Integration mit WP .htaccess erkannt wird, werden die Archivarix-Regeln zu Beginn hinzugefügt.
- Beim Herunterladen von Websites nach Seriennummer wird CDN verwendet, um die Geschwindigkeit zu erhöhen.
- Andere kleinere Verbesserungen und Korrekturen.
- Neues Dashboard zum Anzeigen von Statistiken, Servereinstellungen und Systemaktualisierungen.
- Möglichkeit, Vorlagen zu erstellen und der Site bequem neue Seiten hinzuzufügen.
- Integration mit Wordpress und Joomla mit einem Klick.
- In Search-Substitution wird jetzt eine zusätzliche Filterung in Form eines Konstruktors durchgeführt, in dem Sie eine beliebige Anzahl von Regeln hinzufügen können.
- Jetzt können Sie die Ergebnisse nach Domain / Subdomains, Datum / Uhrzeit und Dateigröße filtern.
- Ein neues Tool zum Zurücksetzen des Caches in Cloudlfare oder zum Aktivieren / Deaktivieren des Dev-Modus.
- Ein neues Tool zum Entfernen der Versionierung in URLs, z. B. "?ver=1.2.3" in CSS oder JS. Ermöglicht die Reparatur auch von Seiten, die im WebArchiv aufgrund fehlender Stile mit unterschiedlichen Versionen schief aussahen.
- Das robots.txt-Tool kann eine Sitemap-Karte sofort aktivieren und hinzufügen.
- Automatische und manuelle Erstellung von Rollback-Punkten für Änderungen.
- Importieren kann Vorlagen importieren.
- Das Speichern / Importieren der Einstellungen des Loaders enthält die erstellten benutzerdefinierten Dateien.
- Für alle Aktionen, die länger als eine Zeitüberschreitung dauern können, wird ein Fortschrittsbalken angezeigt.
- Ein Tool zum Hinzufügen eines Ansichtsfenster-Meta-Tags zu allen Seiten einer Site.
- Tools zum Entfernen defekter Links und Bilder können Dateien auf dem Server berücksichtigen.
- Ein neues Tool zum Beheben falscher Urlencode-Links im HTML-Code. Selten, kann aber nützlich sein.
- Verbessertes Tool für fehlende URLs. Zählt jetzt zusammen mit dem neuen Loader Aufrufe an nicht vorhandene URLs.
- Regex-Tipps für Suche und Substitution.
- Verbesserte Überprüfung auf fehlende PHP-Erweiterungen.
- Alle verwendeten js-Tools wurden auf die neuesten Versionen aktualisiert.
Dies und viele andere kosmetische Verbesserungen und Geschwindigkeitsoptimierungen.